import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
#データ読み込み
wine = pd.read_csv("winequality-white.csv", sep=";", encoding="utf-8")
#データをラベルとデータに分離
y = wine["quality"]
x = wine.drop("quality", axis=1)
#学習用とテスト用に分離
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
#学習する
model = RandomForestClassifier()
model.fit(x_train, y_train)
#評価する
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("正解率 = ", accuracy_score(y_test, y_pred))
precision recall f1-score support
3 0.00 0.00 0.00 2
4 0.62 0.17 0.27 29
5 0.64 0.67 0.65 275
6 0.65 0.75 0.70 468
7 0.68 0.54 0.60 168
8 0.87 0.36 0.51 36
9 0.00 0.00 0.00 2
accuracy 0.66 980
macro avg 0.50 0.36 0.39 980
weighted avg 0.66 0.66 0.65 980
正解率 = 0.6581632653061225
import matplotlib.pyplot as plt
import pandas as pd
#ワインデータの読み込み
wine = pd.read_csv("winequality-white.csv", sep=";", encoding="utf-8")
#品質データごとにグループ分けして、その数を数える
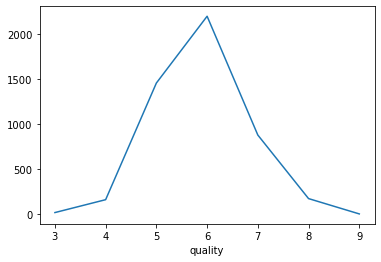
count_data = wine.groupby('quality')["quality"].count()
print(count_data)
#数えたデータをグラフに描画
count_data.plot()
plt.savefig("wine-count-plt.png")
plt.show()
quality
3 20
4 163
5 1457
6 2198
7 880
8 175
9 5
Name: quality, dtype: int64

import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
from sklearn.metrics import classification_report
#データ読み込み
wine = pd.read_csv("winequality-white.csv", sep=";", encoding="utf-8")
#データをラベルとデータに分離
y = wine["quality"]
x = wine.drop("quality", axis=1)
#yのラベルをつけ直す
newlist = []
for v in list(y):
if v <= 4:
newlist += [0]
elif v <= 7:
newlist += [1]
else:
newlist += [2]
y = newlist
#学習用とテスト用に分離
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
#学習する
model = RandomForestClassifier()
model.fit(x_train, y_train)
#評価する
y_pred = model.predict(x_test)
print(classification_report(y_test, y_pred))
print("正解率 = ", accuracy_score(y_test, y_pred))
precision recall f1-score support
0 0.50 0.12 0.19 42
1 0.94 0.99 0.96 900
2 1.00 0.37 0.54 38
accuracy 0.93 980
macro avg 0.81 0.49 0.57 980
weighted avg 0.92 0.93 0.91 980
正解率 = 0.9326530612244898