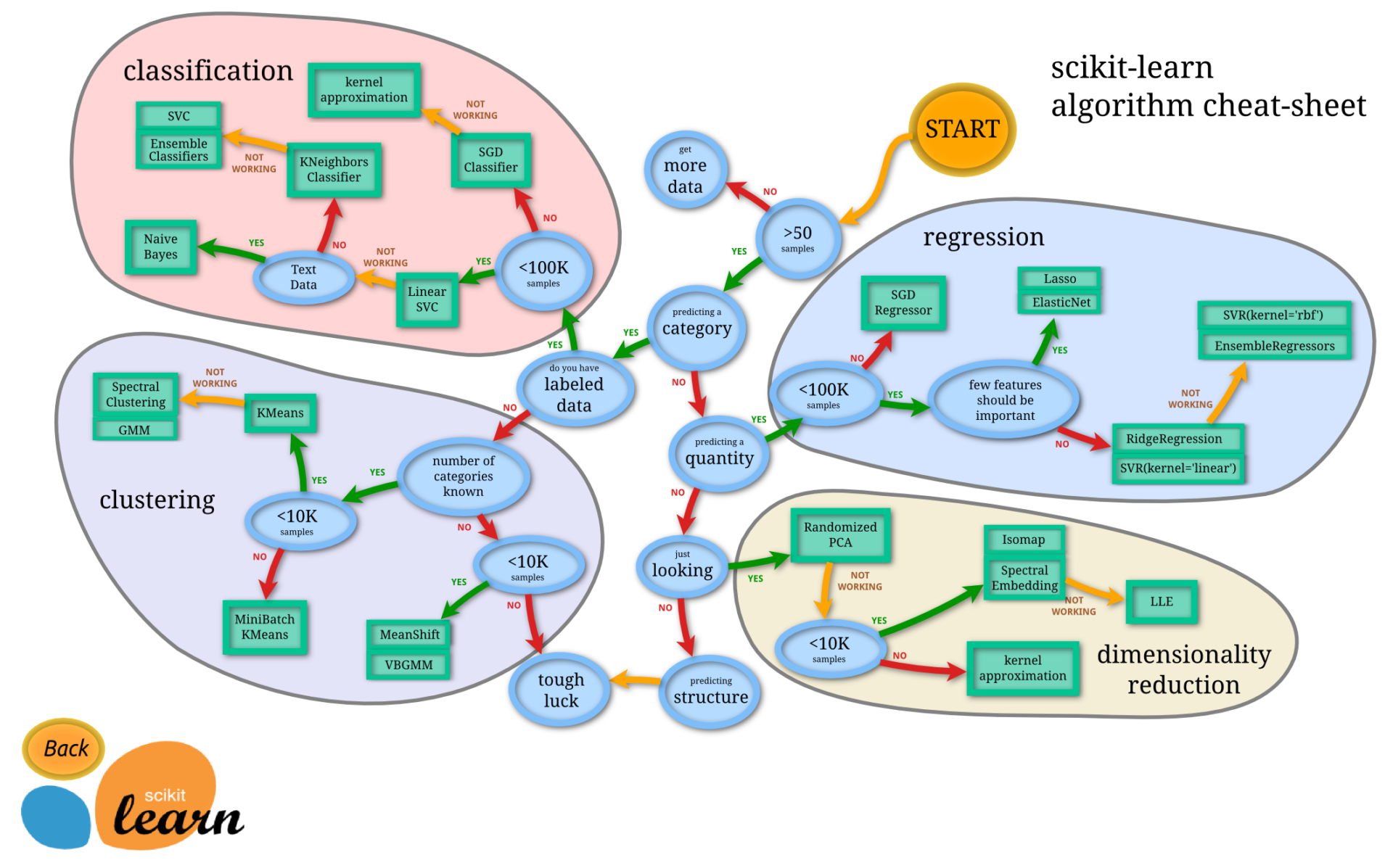
アルゴリズムの選択を行い、ここではLinearSVCを使う。
X and Y
# ライブラリーのインポート
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
# 学習用のデータと結果の準備
# X, Y
learn_data = [[0,0], [1,0], [0,1],[1,1]]
# X and Y
learn_label = [0, 0, 0, 1]
# アルゴリズムの指定
clf = LinearSVC()
# 学習用データと結果の学習 学習にはfit()関数使う
clf.fit(learn_data, learn_label)
# テストデータによる予測 予測にはpredict()関数を使う
test_data = [[0,0], [1,0],[0,1],[1,1]]
test_label = clf.predict(test_data)
# 予測結果の評価
print(test_data, "の予測結果:", test_label)
print("正解率 = ", accuracy_score([0,0,0,1], test_label))[[0, 0], [1, 0], [0, 1], [1, 1]] の予測結果: [0 0 0 1] 正解率 = 1.0
X xor Y
# ライブラリーのインポート
from sklearn.svm import LinearSVC
from sklearn.metrics import accuracy_score
# 学習用のデータと結果の準備
# X, Y
learn_data = [[0,0], [1,0], [0,1],[1,1]]
# X xor Y
learn_label = [0, 1, 1, 0]
# アルゴリズムの指定
clf = LinearSVC()
# 学習用データと結果の学習 学習にはfit()関数使う
clf.fit(learn_data, learn_label)
# テストデータによる予測 予測にはpredict()関数を使う
test_data = [[0,0], [1,0],[0,1],[1,1]]
test_label = clf.predict(test_data)
# 予測結果の評価
print(test_data, "の予測結果:", test_label)
print("正解率 = ", accuracy_score([0,1,1,0], test_label))この場合は正解率が低くなる、XOR計算ができてない。
[[0, 0], [1, 0], [0, 1], [1, 1]] の予測結果: [1 1 1 1]
正解率 = 0.5チャートを確認して、KNeighborsClassiferを使う
# ライブラリーのインポート
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# 学習用のデータと結果の準備
# X, Y
learn_data = [[0,0], [1,0], [0,1],[1,1]]
# X xor Y
learn_label = [0, 1, 1, 0]
# アルゴリズムの指定
clf = KNeighborsClassifier(n_neighbors = 1)
# 学習用データと結果の学習 学習にはfit()関数使う
clf.fit(learn_data, learn_label)
# テストデータによる予測 予測にはpredict()関数を使う
test_data = [[0,0], [1,0],[0,1],[1,1]]
test_label = clf.predict(test_data)
# 予測結果の評価
print(test_data, "の予測結果:", test_label)
print("正解率 = ", accuracy_score([0,1,1,0], test_label))[[0, 0], [1, 0], [0, 1], [1, 1]] の予測結果: [0 1 1 0]
正解率 = 1.0あやめデータを機械学習して正解率を出す
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
#あやめデータの読み込み read_csv()メソッドで読み込み
iris_data = pd.read_csv("iris.csv", encoding="utf-8")
# あやめデータをラベルと入力データに分離する loc()メソッドでヘッダー項目で分離
y = iris_data.loc[:, "Name"]
x = iris_data.loc[:,["SepalLength","SepalWidth","PetalLength","PetalWidth"]]
# 学習用とテスト用に分離する train_test_split()メソッドで分離
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.2, train_size = 0.8, shuffle = True)
# 学習する
clf = SVC()
clf.fit(x_train, y_train)
# 評価する accuracy_score()メソッドで正解率を出す
y_pred = clf.predict(x_test)
print("正解率 = ", accuracy_score(y_test, y_pred))正解率 = 0.9666666666666667