#文字認識 手書き数字の判定
import matplotlib.pyplot as plt
#手書きデータを読み込む
from sklearn import datasets
digits = datasets.load_digits()
#15個連続で出力
for i in range(15):
plt.subplot(3, 5, i+1)
plt.axis("off")
plt.title(str(digits.target[i]))
plt.imshow(digits.images[i], cmap="gray")
plt.show()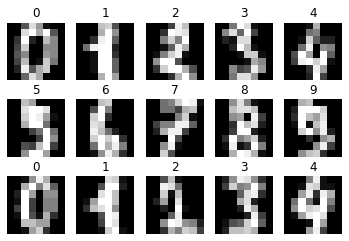
d0 = digits.images[0]
plt.imshow(d0, cmap="gray")
plt.show()
print(d0)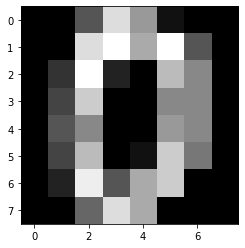
# 画像の機械学習
from sklearn.model_selection import train_test_split
from sklearn import datasets, svm, metrics
from sklearn.metrics import accuracy_score
#データ読み込む
digits = datasets.load_digits()
x = digits.images
y = digits.target
x = x.reshape((-1, 64)) #二次元を1次元配列に変換
#データを学習用とテスト用に分割
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
#データ学習
clf = svm.SVC()
clf.fit(x_train, y_train)
#予測して精度を確認
y_pred = clf.predict(x_test)
print(accuracy_score(y_test, y_pred))0.9888888888888889
# 学習済みデータを保存
import pickle
with open("digits.pkl", "wb") as fp:
pickle.dump(clf, fp)#学習済みデータを読み込む
import pickle
with open("digits.pkl","rb") as fp:
clf = pickle.load(fp)#用意した画像の判定
import cv2
import pickle
def predict_digit(filename):
#学習済みデータを読み込む
with open("digits.pkl","rb") as fp:
clf = pickle.load(fp)
#自分で用意した画像ファイルを読む
my_img = cv2.imread(filename)
#画像データを学習済みデータに合わせる
my_img = cv2.cvtColor(my_img, cv2.COLOR_BGR2GRAY)
my_img = cv2.resize(my_img, (8,8))
my_img = 15 - my_img // 16
#二次元を一次元に変換
my_img = my_img.reshape((-1, 64))
#データ予測
res = clf.predict(my_img)
return res[0]
#画像ファイルを指定して実行
n = predict_digit("my2.png")
print("my2.png = " + str(n))
n = predict_digit("my4.png")
print("my4.png = " + str(n))
n = predict_digit("my9.png")
print("my9.png = " + str(n))my2.png = 2
my4.png = 4
my9.png = 9THE MINIST DATABASE of handwritten digits
http://yann.lecun.com/exdb/mnist/

